Setting up LM Studio
If you want to run LM Studio, you need either a Mac with an M1 (or subsequent) CPU, or a Windows system with a CPU that offers support for AVX2 extensions. The requirements for both memory (RAM and hard drive space) are dependent on your selected LLM. Some are relatively small, coming in at just a few GB, whilst larger models might consume substantial storage and memory. While GPU acceleration is currently considered to be experimental, it’s not a necessity in order to operate most LLMs. The newest Mac and Windows installers can be downloaded from https://lmstudio.ai/, and a version for Linux is currently being trialled.
Procuring a model
LM Studio has a built-in search function that uses the Hugging Face AI community API to search for models. For demonstration purposes, I will use Meta’s Llama 2 model. Note that model availability and performance change daily. Enter the keywords llama gguf in the search bar. Because Hugging Face also contains models incompatible with LM Studio, I added the GGUF specification. GPT-Generated Unified Format (GGUF) is a file format for LLMs.
LM’s model search interface
Searching LLMs in LM Studio
The models you will see are filtered by potential compatibility with your system and ordered by popularity.
The most popular selection currently is TheBloke/Llama-2-7B-Chat-GGUF as per Meta. Details about the model can be obtained from the Model Card which is a source of information from the developer of the model. This model is available with multiple quantization settings, a technique for streamlining a model by using fewer resources by downscaling the model’s precision.
In my situation, I will opt for Q5_K_M, which necessitates approximately 8GB of RAM and 5GB of disk space. Select the most suitable option based on your situation and resources. After selection, click Download.
Inspect the Model Card button to find out more about the model
How to Run an LLM on your desktop
Click the AI Chat icon in the navigation panel on the left side. At the top, select a model to load and click the llama 2 chat option. It takes a few seconds to load.
LM Studio may ask whether to override the default LM Studio prompt with the prompt the developer suggests. A prompt suggests specific roles, intent, and limitations to the model, e.g., “You are a helpful coding AI assistant,” which the model will then use as context for answering your prompts. Note that accepting a prompt (input) from a third party may have unintended side effects; you can review the prompt in the model settings.
On the right side, you also have various settings for your specific models, which can be used to fine-tune both performance and resource consumption. Experimental GPU support is available. You can now converse with the downloaded model.
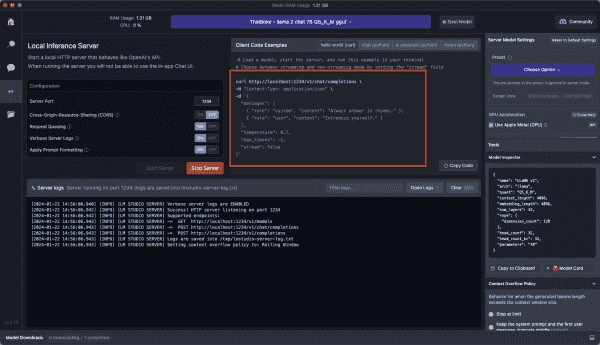
Running a local LLM server
LM Studio also allows you to run a downloaded model as a server. This is useful for developing and testing your code. The server is compatible with the OpenAI API, currently the most popular API for LLMs.
Click on the Local Server option in the navigation bar. Note that starting a server disables the Chat option. Once again, you can change various features or use a preset, but the defaults should work fine. Click Start Server.
The LM Server runs on port 1234 by default, and you access the API via HTTP.
If you installed the OpenAI SDK for Python, you can access the LM Server by simply replacing client = OpenAI() with client = OpenAI(base_url=”http://localhost:1234/v1″, api_key=”not-needed”). The best part is you don’t need an OpenAI API key.
Instead of conversing with one of the OpenAI models, you will access a model installed on your desktop. In our case, this is Meta’s Llama 2.
You can view the model’s response in the LM Studio Server Logs.